
🔗 Colab Notebook
🔗 GitHub
How to store and process data in a distributed way so that it can be used for marketing campaign by a bank?
Problem Statement: A bank wants to run a marketing campaign. It is getting data from various 3rd party sources. Before running the campaign it needs to process and clean the data. The data needs to be stored and processed in distributed way.
- Hadoop is used for distributed storage.
- Spark is used for distributed processing.
Transformations Performed:
- Filtering ‘unknown’ values in the Country column
- Converting Age to integer type and Salary to float type
- Replacing null values in Age and Salary with their respective mean values.
Finally the transformed file is saved for further use.
The same project can be implemented in Dataproc: The bank prospects.csv file is stored in HDFS. The same above code is stored as bank_prospects_transformation.py file using nano editor
The following commands are used:
# To copy the data from master node to HDFS worker nodes
hadoop fs -ls put bank_prospects.csv /user/username/data
# Open nano editor and write the spark code
nano bank_transformation.py
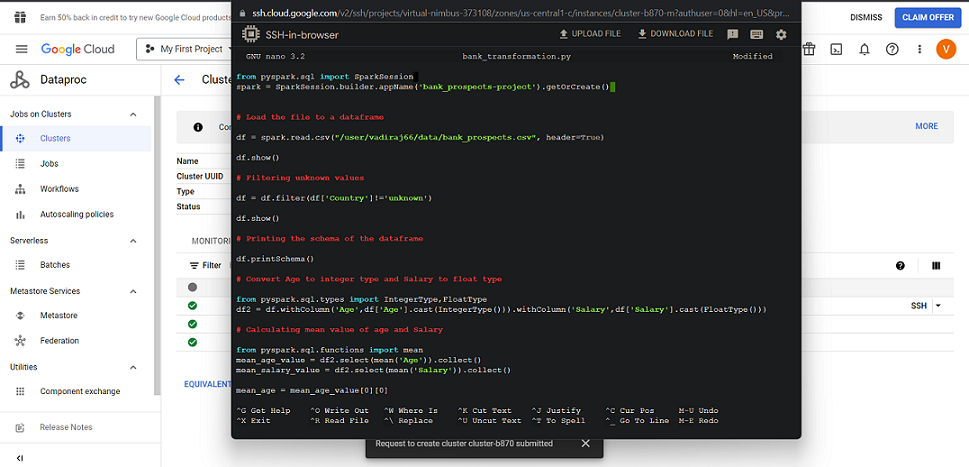
The code is submitted to the spark cluster using spark-submit command
spark-submit bank_transformation.py
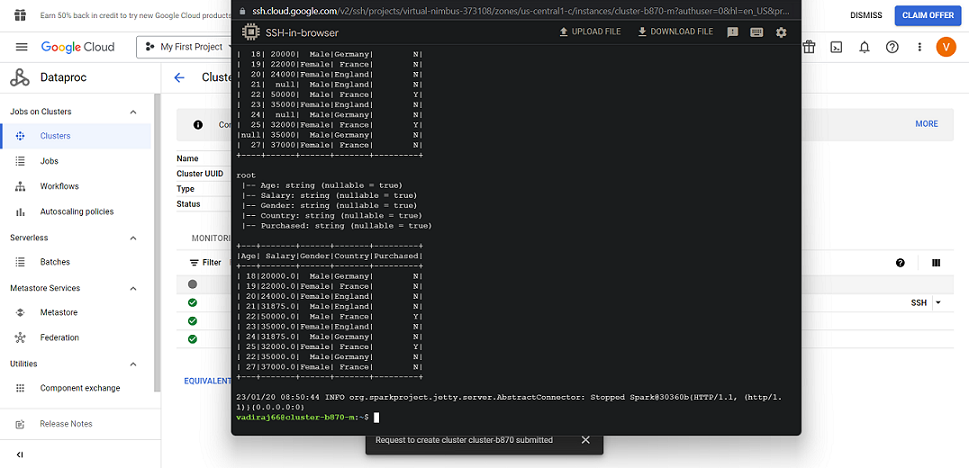
A hive table is created which points to the transformed data in HDFS so that anybody who wants to access the transformed data and perform analytics they can connect to this hive table.
The following commands are used
hive
>create database if not exists bankDB;
>use bankDB;
>create table bankprospectscleaned (age INT,salary FLOAT,gender STRING, country STRING,purchased STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/user/vadiraj66/data/bank_prospects_transformed/' TBLPROPERTIES ("skip.header.line.count"="1");